
Category
AI Engineering
Browse the latest posts in this category.
All Posts
Why Your AI Background Job Is Probably Lying to You
Most AI processing pipelines look like they work until one crash reveals they have been silently duplicating data, swallowing failures, and pretending retries are safe. This is the full story of breaking a production pipeline and rebuilding it the right way.
MUMuhammad Umar Aziz

From Retrieval to Production: Reranking, Caching, and the Streaming Architecture Behind Real-Scale RAG
Part 1 covered what to store and how to retrieve it. Part 2 covers what breaks when real users arrive — and how production systems like Perplexity and ChatGPT are actually wired to handle it
MUMuhammad Umar Aziz
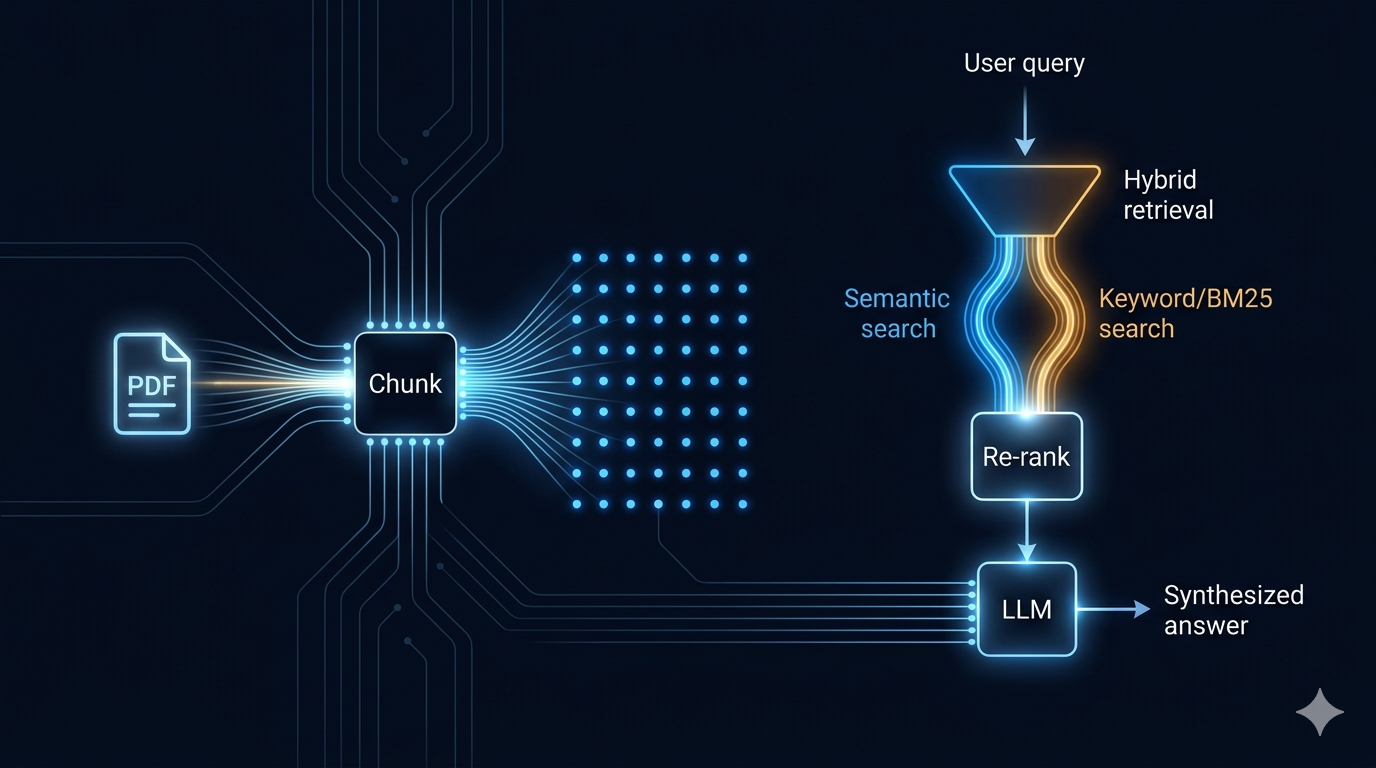
The Engineering Behind a RAG (Retrieval-Augmented Generation)
Most RAG tutorials show you how to build something that works in a notebook. This one shows you what it takes to make it work when a real user shows up.
MUMuhammad Umar Aziz